Reproducible Builds: Reproducible Builds in April 2024
 Welcome to the April 2024 report from the Reproducible Builds project! In our reports, we attempt to outline what we have been up to over the past month, as well as mentioning some of the important things happening more generally in software supply-chain security. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Table of contents:
Welcome to the April 2024 report from the Reproducible Builds project! In our reports, we attempt to outline what we have been up to over the past month, as well as mentioning some of the important things happening more generally in software supply-chain security. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Table of contents:
- New
backseat-signedtool to validate distributions source inputs - NixOS is not reproducible
- Certificate vulnerabilities in F-Droid s
fdroidserver - Website updates
- Reproducible Builds and Insights from an Independent Verifier for Arch Linux
libntlmnow releasing minimal source-only tarballs- Distribution work
- Mailing list news
- diffoscope
- Upstream patches
- reprotest
- Reproducibility testing framework
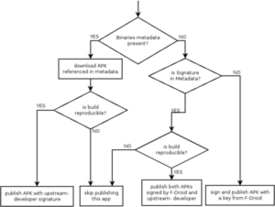
New backseat-signed tool to validate distributions source inputs
kpcyrd announced a new tool called backseat-signed, after:
I figured out a somewhat straight-forward way to check if a given git archive output is cryptographically claimed to be the source input of a given binary package in either Arch Linux or Debian (or both).
Elaborating more in their announcement post, kpcyrd writes:
I believe this to be the reproducible source tarball thing some people have been asking about. As explained in the README, I believe reproducing autotools-generated tarballs isn t worth everybody s time and instead a distribution that claims to build from source should operate on VCS snapshots instead of tarballs with 25k lines of pre-generated shell-script.
Indeed, many distributions packages already build from VCS snapshots, and this trend is likely to accelerate in response to the xz incident. The announcement led to a lengthy discussion on our mailing list, as well as shorter followup thread from kpcyrd about bootstrapping Autotools projects.
NixOS is not reproducible
 Morten Linderud posted an post on his blog this month, provocatively titled, NixOS is not reproducible . Although quickly admitting that his title is indeed clickbait , Morten goes on to clarify the precise guarantees and promises that NixOS provides its users.
Later in the most, Morten mentions that he was motivated to write the post because:
Morten Linderud posted an post on his blog this month, provocatively titled, NixOS is not reproducible . Although quickly admitting that his title is indeed clickbait , Morten goes on to clarify the precise guarantees and promises that NixOS provides its users.
Later in the most, Morten mentions that he was motivated to write the post because:
I have heavily invested my free-time on this topic since 2017, and met some of the accomplishments we have had with Doesn t NixOS solve this? for just as long and I thought it would be of peoples interest to clarify[.]
Certificate vulnerabilities in F-Droid s fdroidserver
In early April, Fay Stegerman announced a certificate pinning bypass vulnerability and Proof of Concept (PoC) in the F-Droid fdroidserver tools for managing builds, indexes, updates, and deployments for F-Droid repositories to the oss-security mailing list.
We observed that embedding a v1 (JAR) signature file in an APK with minSdk >= 24 will be ignored by Android/apksigner, which only checks v2/v3 in that case. However, since fdroidserver checks v1 first, regardless of minSdk, and does not verify the signature, it will accept a fake certificate and see an incorrect certificate fingerprint. [ ] We also realised that the above mentioned discrepancy between apksigner and androguard (which fdroidserver uses to extract the v2/v3 certificates) can be abused here as well. [ ]
Later on in the month, Fay followed up with a second post detailing a third vulnerability and a script that could be used to scan for potentially affected .apk files and mentioned that, whilst upstream had acknowledged the vulnerability, they had not yet applied any ameliorating fixes.
Website updates
 There were a number of improvements made to our website this month, including Chris Lamb updating the archive page to recommend
There were a number of improvements made to our website this month, including Chris Lamb updating the archive page to recommend -X and unzipping with TZ=UTC [ ] and adding Maven, Gradle, JDK and Groovy examples to the SOURCE_DATE_EPOCH page [ ]. In addition Jan Zerebecki added a new /contribute/opensuse/ page [ ] and Sertonix fixed the automatic RSS feed detection [ ][ ].
Reproducible Builds and Insights from an Independent Verifier for Arch Linux
 Joshua Drexel, Esther H nggi and Iy n M ndez Veiga of the School of Computer Science and Information Technology, Hochschule Luzern (HSLU) in Switzerland published a paper this month entitled Reproducible Builds and Insights from an Independent Verifier for Arch Linux. The paper establishes the context as follows:
Joshua Drexel, Esther H nggi and Iy n M ndez Veiga of the School of Computer Science and Information Technology, Hochschule Luzern (HSLU) in Switzerland published a paper this month entitled Reproducible Builds and Insights from an Independent Verifier for Arch Linux. The paper establishes the context as follows:
Supply chain attacks have emerged as a prominent cybersecurity threat in recent years. Reproducible and bootstrappable builds have the potential to reduce such attacks significantly. In combination with independent, exhaustive and periodic source code audits, these measures can effectively eradicate compromises in the building process. In this paper we introduce both concepts, we analyze the achievements over the last ten years and explain the remaining challenges.
What is more, the paper aims to:
contribute to the reproducible builds effort by setting up a rebuilder and verifier instance to test the reproducibility of Arch Linux packages. Using the results from this instance, we uncover an unnoticed and security-relevant packaging issue affecting 16 packages related to Certbot [ ].
A PDF of the paper is available.
libntlm now releasing minimal source-only tarballs
Simon Josefsson wrote on his blog this month that, going forward, the libntlm project will now be releasing what they call minimal source-only tarballs :
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. [The] risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions [ship] generated files coming from the tarball into the binary *.deb or *.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built[.]
Simon s post goes into further details how this was achieved, and describes some potential caveats and counters some expected responses as well. A shorter version can be found in the announcement for the 1.8 release of libntlm.
Distribution work
 In Debian this month, Helmut Grohne filed a bug suggesting the removal of
In Debian this month, Helmut Grohne filed a bug suggesting the removal of dh-buildinfo, a tool to generate and distribute .buildinfo-like files within binary packages. Note that this is distinct from the .buildinfo generation performed by dpkg-genbuildinfo. By contrast, the entirely optional dh-buildinfo generated a debian/buildinfo file that would be shipped within binary packages as /usr/share/doc/package/buildinfo_$arch.gz.
Adrian Bunk recently asked about including source hashes in Debian s .buildinfo files, which prompted Guillem Jover to refresh some old patches to dpkg to make this possible, which revealed some quirks Vagrant Cascadian discovered when testing.
In addition, 21 reviews of Debian packages were added, 22 were updated and 16 were removed this month adding to our knowledge about identified issues. A number issue types have been added, such as new random_temporary_filenames_embedded_by_mesonpy and timestamps_added_by_librime toolchain issues.
 In openSUSE, it was announced that their Factory distribution enabled bit-by-bit reproducible builds for almost all parts of the package. Previously, more parts needed to be ignored when comparing package files, but now only the signature needs to be deleted.
In addition, Bernhard M. Wiedemann published
In openSUSE, it was announced that their Factory distribution enabled bit-by-bit reproducible builds for almost all parts of the package. Previously, more parts needed to be ignored when comparing package files, but now only the signature needs to be deleted.
In addition, Bernhard M. Wiedemann published theunreproduciblepackage as a proper .rpm package which it allows to better test tools intended to debug reproducibility. Furthermore, it was announced that Bernhard s work on a 100% reproducible openSUSE-based distribution will be funded by NLnet.
He also posted another monthly report for his reproducibility work in openSUSE.
 In GNU Guix, Janneke Nieuwenhuizen submitted a patch set for creating a reproducible source tarball for Guix. That is to say, ensuring that
In GNU Guix, Janneke Nieuwenhuizen submitted a patch set for creating a reproducible source tarball for Guix. That is to say, ensuring that make dist is reproducible when run from Git. [ ]
 Lastly, in Fedora, a new wiki page was created to propose a change to the distribution. Titled Changes/ReproduciblePackageBuilds , the page summarises itself as a proposal whereby A post-build cleanup is integrated into the RPM build process so that common causes of build irreproducibility in packages are removed, making most of Fedora packages reproducible.
Lastly, in Fedora, a new wiki page was created to propose a change to the distribution. Titled Changes/ReproduciblePackageBuilds , the page summarises itself as a proposal whereby A post-build cleanup is integrated into the RPM build process so that common causes of build irreproducibility in packages are removed, making most of Fedora packages reproducible.
Mailing list news
On our mailing list this month:
-
Continuing a thread started in March 2024 about the Arch Linux minimal container now being 100% reproducible, John Gilmore followed up with a post about the practical and philosophical distinctions of local vs. remote storage of the various artifacts needed to build packages.
-
Chris Lamb asked the list which conferences readers are attending these days: After peak Covid and other industry-wide changes, conferences are no longer the must attend events they previously were especially in the area of software supply-chain security. In rough, practical terms, it seems harder to justify conference travel today than it did in mid-2019. The thread generated a number of responses which would be of interest to anyone planning travel in Q3 and Q4 of 2024.
-
James Addison wrote to the list about a quirk in Git related to its
core.autocrlf functionality, thus helpfully passing on a slightly off-topic and perhaps not of direct relevance to anyone on the list today note that might still be the kind of issue that is useful to be aware of if-and-when puzzling over unexpected git content / checksum issues (situations that I do expect people on this list encounter from time-to-time) .
diffoscope
 diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 263, 264 and 265 to Debian and made the following additional changes:
- Don t crash on invalid
.zip files, even if we encounter their badness halfway through the file and not at the time of their initial opening. [ ]
- Prevent
odt2txt tests from always being skipped due to an (impossibly) new version requirement. [ ]
- Avoid parens-in-parens in test skipping messages. [ ]
- Ensure that tests with
>=-style version constraints actually print the tool name. [ ]
In addition, Fay Stegerman fixed a crash when there are (invalid) duplicate entries in .zip which was originally reported in Debian bug #1068705). [ ] Fay also added a user-visible note to a diff when there are duplicate entries in ZIP files [ ]. Lastly, Vagrant Cascadian added an external tool pointer for the zipdetails tool under GNU Guix [ ] and proposed updates to diffoscope in Guix as well [ ] which were merged as [264] [265], fixed a regression in test coverage and increased verbosity of the test suite[ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Chris Lamb:
- #1068173 filed against
pg-gvm.
- #1068176 filed against
goldendict-ng.
- #1068372 filed against
grokevt.
- #1068374 filed against
ttconv.
- #1068375 filed against
ludevit.
- #1068795 filed against
pympress.
- #1069168 filed against
sagemath-database-conway-polynomials.
- #1069169 filed against
gap-polymaking.
- #1069663 filed against
dub.
- #1069709 filed against
dpb.
- #1069784 filed against
python-itemloaders.
- #1069822 filed against
python-gvm.
-
Bernhard M. Wiedemann:
metis (fix build with nocheck)musique (fix a date-related issue)orthanc-volview (fix an issue with mtimes and sorting)go1.13, go1.14, go1.15 (fix a parallelism-related issue)postfish (disable compile-time benchmarking)geany/glfw (toolchain, random)edk2/ovmf/tianocore (with Joey Li: fix a date-related issue)dlib (report an issue with compile-time-CPU-detection)lua-lmod (fix a date-related issue)gitui (fix a date-related issue)openssl-3 (report an issue with random output)gcc14 (FTBFS-2038)nebula (FTBFS-2027-11-11)
-
Jan Zerebecki:
- rpm (Support reproducible automatic rebuilds, etc.)
- openSUSE-release-tools (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- pesign-obs-integration (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- openSUSE post-build-checks (Set
SOURCE_DATE_EPOCH)
- obs-build (Fix changelog timezone handling)
- obs-service-tar_scm (When generating changelog from Git, create the file if it does not exist.)
-
Thomas Goirand:
oslo.messaging (fix a hostname-related issue)
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, reprotest version 0.7.27 was uploaded to Debian unstable) by Vagrant Cascadian who made the following additional changes:
- Enable specific number of CPUs using
--vary=num_cpus.cpus=X. [ ]
- Consistently use 398 days for time variation, rather than choosing randomly each time. [ ]
- Disable builds of
arch:any packages. [ ]
- Update the description for the
build_path.path option in README.rst. [ ]
- Update escape sequences for compatibility with Python 3.12. (#1068853). [ ]
- Remove the generic upstream signing-key [ ] and update the packages signing key with the currently active team members [ ].
- Update the packaging
Standards-Version to 4.7.0. [ ]
In addition, Holger Levsen fixed some spelling errors detected by the spellintian tool [ ] and Vagrant Cascadian updated reprotest in GNU Guix to 0.7.27.
Reproducibility testing framework
 The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In April, an enormous number of changes were made by Holger Levsen:
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In April, an enormous number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Breakage detection:
- Exclude currently building packages from breakage detection. [ ]
- Be more noisy if diffoscope crashes. [ ]
- Health check: provide clickable URLs in jenkins job log for failed pkg builds due to diffoscope crashes. [ ]
- Limit graph to about the last 100 days of breakages only. [ ]
- Fix all found files with bad permissions. [ ]
- Prepare dealing with diffoscope timeouts. [ ]
- Detect more cases of failure to debootstrap base system. [ ]
- Include timestamps of failed job runs. [ ]
-
Documentation updates:
- Document how to access arm64 nodes at Codethink. [ ]
- Document how to use infomaniak.cloud. [ ]
- Drop notes about long stalled LeMaker HiKey960 boards sponsored by HPE and hosted at ETH. [ ]
- Mention
osuosl4 and osuosl5 and explain their usage. [ ]
- Mention that some packages are built differently. [ ][ ]
- Improve language in a comment. [ ]
- Add more notes how to query resource usage from
infomaniak.cloud. [ ]
-
Node maintenance:
-
Misc changes:
In addition, Mattia Rizzolo added some new host details. [ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
git archive output is cryptographically claimed to be the source input of a given binary package in either Arch Linux or Debian (or both).
Morten Linderud posted an post on his blog this month, provocatively titled, NixOS is not reproducible . Although quickly admitting that his title is indeed clickbait , Morten goes on to clarify the precise guarantees and promises that NixOS provides its users.
Later in the most, Morten mentions that he was motivated to write the post because:
I have heavily invested my free-time on this topic since 2017, and met some of the accomplishments we have had with Doesn t NixOS solve this? for just as long and I thought it would be of peoples interest to clarify[.]
Certificate vulnerabilities in F-Droid s fdroidserver
In early April, Fay Stegerman announced a certificate pinning bypass vulnerability and Proof of Concept (PoC) in the F-Droid fdroidserver tools for managing builds, indexes, updates, and deployments for F-Droid repositories to the oss-security mailing list.
We observed that embedding a v1 (JAR) signature file in an APK with minSdk >= 24 will be ignored by Android/apksigner, which only checks v2/v3 in that case. However, since fdroidserver checks v1 first, regardless of minSdk, and does not verify the signature, it will accept a fake certificate and see an incorrect certificate fingerprint. [ ] We also realised that the above mentioned discrepancy between apksigner and androguard (which fdroidserver uses to extract the v2/v3 certificates) can be abused here as well. [ ]
Later on in the month, Fay followed up with a second post detailing a third vulnerability and a script that could be used to scan for potentially affected .apk files and mentioned that, whilst upstream had acknowledged the vulnerability, they had not yet applied any ameliorating fixes.
Website updates
There were a number of improvements made to our website this month, including Chris Lamb updating the archive page to recommend -X and unzipping with TZ=UTC [ ] and adding Maven, Gradle, JDK and Groovy examples to the SOURCE_DATE_EPOCH page [ ]. In addition Jan Zerebecki added a new /contribute/opensuse/ page [ ] and Sertonix fixed the automatic RSS feed detection [ ][ ].
Reproducible Builds and Insights from an Independent Verifier for Arch Linux
Joshua Drexel, Esther H nggi and Iy n M ndez Veiga of the School of Computer Science and Information Technology, Hochschule Luzern (HSLU) in Switzerland published a paper this month entitled Reproducible Builds and Insights from an Independent Verifier for Arch Linux. The paper establishes the context as follows:
Supply chain attacks have emerged as a prominent cybersecurity threat in recent years. Reproducible and bootstrappable builds have the potential to reduce such attacks significantly. In combination with independent, exhaustive and periodic source code audits, these measures can effectively eradicate compromises in the building process. In this paper we introduce both concepts, we analyze the achievements over the last ten years and explain the remaining challenges.
What is more, the paper aims to:
contribute to the reproducible builds effort by setting up a rebuilder and verifier instance to test the reproducibility of Arch Linux packages. Using the results from this instance, we uncover an unnoticed and security-relevant packaging issue affecting 16 packages related to Certbot [ ].
A PDF of the paper is available.
libntlm now releasing minimal source-only tarballs
Simon Josefsson wrote on his blog this month that, going forward, the libntlm project will now be releasing what they call minimal source-only tarballs :
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. [The] risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions [ship] generated files coming from the tarball into the binary *.deb or *.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built[.]
Simon s post goes into further details how this was achieved, and describes some potential caveats and counters some expected responses as well. A shorter version can be found in the announcement for the 1.8 release of libntlm.
Distribution work
In Debian this month, Helmut Grohne filed a bug suggesting the removal of dh-buildinfo, a tool to generate and distribute .buildinfo-like files within binary packages. Note that this is distinct from the .buildinfo generation performed by dpkg-genbuildinfo. By contrast, the entirely optional dh-buildinfo generated a debian/buildinfo file that would be shipped within binary packages as /usr/share/doc/package/buildinfo_$arch.gz.
Adrian Bunk recently asked about including source hashes in Debian s .buildinfo files, which prompted Guillem Jover to refresh some old patches to dpkg to make this possible, which revealed some quirks Vagrant Cascadian discovered when testing.
In addition, 21 reviews of Debian packages were added, 22 were updated and 16 were removed this month adding to our knowledge about identified issues. A number issue types have been added, such as new random_temporary_filenames_embedded_by_mesonpy and timestamps_added_by_librime toolchain issues.
In openSUSE, it was announced that their Factory distribution enabled bit-by-bit reproducible builds for almost all parts of the package. Previously, more parts needed to be ignored when comparing package files, but now only the signature needs to be deleted.
In addition, Bernhard M. Wiedemann published theunreproduciblepackage as a proper .rpm package which it allows to better test tools intended to debug reproducibility. Furthermore, it was announced that Bernhard s work on a 100% reproducible openSUSE-based distribution will be funded by NLnet.
He also posted another monthly report for his reproducibility work in openSUSE.
In GNU Guix, Janneke Nieuwenhuizen submitted a patch set for creating a reproducible source tarball for Guix. That is to say, ensuring that make dist is reproducible when run from Git. [ ]
Lastly, in Fedora, a new wiki page was created to propose a change to the distribution. Titled Changes/ReproduciblePackageBuilds , the page summarises itself as a proposal whereby A post-build cleanup is integrated into the RPM build process so that common causes of build irreproducibility in packages are removed, making most of Fedora packages reproducible.
Mailing list news
On our mailing list this month:
-
Continuing a thread started in March 2024 about the Arch Linux minimal container now being 100% reproducible, John Gilmore followed up with a post about the practical and philosophical distinctions of local vs. remote storage of the various artifacts needed to build packages.
-
Chris Lamb asked the list which conferences readers are attending these days: After peak Covid and other industry-wide changes, conferences are no longer the must attend events they previously were especially in the area of software supply-chain security. In rough, practical terms, it seems harder to justify conference travel today than it did in mid-2019. The thread generated a number of responses which would be of interest to anyone planning travel in Q3 and Q4 of 2024.
-
James Addison wrote to the list about a quirk in Git related to its
core.autocrlf functionality, thus helpfully passing on a slightly off-topic and perhaps not of direct relevance to anyone on the list today note that might still be the kind of issue that is useful to be aware of if-and-when puzzling over unexpected git content / checksum issues (situations that I do expect people on this list encounter from time-to-time) .
diffoscope
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 263, 264 and 265 to Debian and made the following additional changes:
- Don t crash on invalid
.zip files, even if we encounter their badness halfway through the file and not at the time of their initial opening. [ ]
- Prevent
odt2txt tests from always being skipped due to an (impossibly) new version requirement. [ ]
- Avoid parens-in-parens in test skipping messages. [ ]
- Ensure that tests with
>=-style version constraints actually print the tool name. [ ]
In addition, Fay Stegerman fixed a crash when there are (invalid) duplicate entries in .zip which was originally reported in Debian bug #1068705). [ ] Fay also added a user-visible note to a diff when there are duplicate entries in ZIP files [ ]. Lastly, Vagrant Cascadian added an external tool pointer for the zipdetails tool under GNU Guix [ ] and proposed updates to diffoscope in Guix as well [ ] which were merged as [264] [265], fixed a regression in test coverage and increased verbosity of the test suite[ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Chris Lamb:
- #1068173 filed against
pg-gvm.
- #1068176 filed against
goldendict-ng.
- #1068372 filed against
grokevt.
- #1068374 filed against
ttconv.
- #1068375 filed against
ludevit.
- #1068795 filed against
pympress.
- #1069168 filed against
sagemath-database-conway-polynomials.
- #1069169 filed against
gap-polymaking.
- #1069663 filed against
dub.
- #1069709 filed against
dpb.
- #1069784 filed against
python-itemloaders.
- #1069822 filed against
python-gvm.
-
Bernhard M. Wiedemann:
metis (fix build with nocheck)musique (fix a date-related issue)orthanc-volview (fix an issue with mtimes and sorting)go1.13, go1.14, go1.15 (fix a parallelism-related issue)postfish (disable compile-time benchmarking)geany/glfw (toolchain, random)edk2/ovmf/tianocore (with Joey Li: fix a date-related issue)dlib (report an issue with compile-time-CPU-detection)lua-lmod (fix a date-related issue)gitui (fix a date-related issue)openssl-3 (report an issue with random output)gcc14 (FTBFS-2038)nebula (FTBFS-2027-11-11)
-
Jan Zerebecki:
- rpm (Support reproducible automatic rebuilds, etc.)
- openSUSE-release-tools (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- pesign-obs-integration (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- openSUSE post-build-checks (Set
SOURCE_DATE_EPOCH)
- obs-build (Fix changelog timezone handling)
- obs-service-tar_scm (When generating changelog from Git, create the file if it does not exist.)
-
Thomas Goirand:
oslo.messaging (fix a hostname-related issue)
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, reprotest version 0.7.27 was uploaded to Debian unstable) by Vagrant Cascadian who made the following additional changes:
- Enable specific number of CPUs using
--vary=num_cpus.cpus=X. [ ]
- Consistently use 398 days for time variation, rather than choosing randomly each time. [ ]
- Disable builds of
arch:any packages. [ ]
- Update the description for the
build_path.path option in README.rst. [ ]
- Update escape sequences for compatibility with Python 3.12. (#1068853). [ ]
- Remove the generic upstream signing-key [ ] and update the packages signing key with the currently active team members [ ].
- Update the packaging
Standards-Version to 4.7.0. [ ]
In addition, Holger Levsen fixed some spelling errors detected by the spellintian tool [ ] and Vagrant Cascadian updated reprotest in GNU Guix to 0.7.27.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In April, an enormous number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Breakage detection:
- Exclude currently building packages from breakage detection. [ ]
- Be more noisy if diffoscope crashes. [ ]
- Health check: provide clickable URLs in jenkins job log for failed pkg builds due to diffoscope crashes. [ ]
- Limit graph to about the last 100 days of breakages only. [ ]
- Fix all found files with bad permissions. [ ]
- Prepare dealing with diffoscope timeouts. [ ]
- Detect more cases of failure to debootstrap base system. [ ]
- Include timestamps of failed job runs. [ ]
-
Documentation updates:
- Document how to access arm64 nodes at Codethink. [ ]
- Document how to use infomaniak.cloud. [ ]
- Drop notes about long stalled LeMaker HiKey960 boards sponsored by HPE and hosted at ETH. [ ]
- Mention
osuosl4 and osuosl5 and explain their usage. [ ]
- Mention that some packages are built differently. [ ][ ]
- Improve language in a comment. [ ]
- Add more notes how to query resource usage from
infomaniak.cloud. [ ]
-
Node maintenance:
-
Misc changes:
In addition, Mattia Rizzolo added some new host details. [ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
minSdk >= 24 will be ignored by Android/apksigner, which only checks v2/v3 in that case. However, since fdroidserver checks v1 first, regardless of minSdk, and does not verify the signature, it will accept a fake certificate and see an incorrect certificate fingerprint. [ ] We also realised that the above mentioned discrepancy between apksigner and androguard (which fdroidserver uses to extract the v2/v3 certificates) can be abused here as well. [ ]
There were a number of improvements made to our website this month, including Chris Lamb updating the archive page to recommend -X and unzipping with TZ=UTC [ ] and adding Maven, Gradle, JDK and Groovy examples to the SOURCE_DATE_EPOCH page [ ]. In addition Jan Zerebecki added a new /contribute/opensuse/ page [ ] and Sertonix fixed the automatic RSS feed detection [ ][ ].
Reproducible Builds and Insights from an Independent Verifier for Arch Linux
Joshua Drexel, Esther H nggi and Iy n M ndez Veiga of the School of Computer Science and Information Technology, Hochschule Luzern (HSLU) in Switzerland published a paper this month entitled Reproducible Builds and Insights from an Independent Verifier for Arch Linux. The paper establishes the context as follows:
Supply chain attacks have emerged as a prominent cybersecurity threat in recent years. Reproducible and bootstrappable builds have the potential to reduce such attacks significantly. In combination with independent, exhaustive and periodic source code audits, these measures can effectively eradicate compromises in the building process. In this paper we introduce both concepts, we analyze the achievements over the last ten years and explain the remaining challenges.
What is more, the paper aims to:
contribute to the reproducible builds effort by setting up a rebuilder and verifier instance to test the reproducibility of Arch Linux packages. Using the results from this instance, we uncover an unnoticed and security-relevant packaging issue affecting 16 packages related to Certbot [ ].
A PDF of the paper is available.
libntlm now releasing minimal source-only tarballs
Simon Josefsson wrote on his blog this month that, going forward, the libntlm project will now be releasing what they call minimal source-only tarballs :
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. [The] risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions [ship] generated files coming from the tarball into the binary *.deb or *.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built[.]
Simon s post goes into further details how this was achieved, and describes some potential caveats and counters some expected responses as well. A shorter version can be found in the announcement for the 1.8 release of libntlm.
Distribution work
In Debian this month, Helmut Grohne filed a bug suggesting the removal of dh-buildinfo, a tool to generate and distribute .buildinfo-like files within binary packages. Note that this is distinct from the .buildinfo generation performed by dpkg-genbuildinfo. By contrast, the entirely optional dh-buildinfo generated a debian/buildinfo file that would be shipped within binary packages as /usr/share/doc/package/buildinfo_$arch.gz.
Adrian Bunk recently asked about including source hashes in Debian s .buildinfo files, which prompted Guillem Jover to refresh some old patches to dpkg to make this possible, which revealed some quirks Vagrant Cascadian discovered when testing.
In addition, 21 reviews of Debian packages were added, 22 were updated and 16 were removed this month adding to our knowledge about identified issues. A number issue types have been added, such as new random_temporary_filenames_embedded_by_mesonpy and timestamps_added_by_librime toolchain issues.
In openSUSE, it was announced that their Factory distribution enabled bit-by-bit reproducible builds for almost all parts of the package. Previously, more parts needed to be ignored when comparing package files, but now only the signature needs to be deleted.
In addition, Bernhard M. Wiedemann published theunreproduciblepackage as a proper .rpm package which it allows to better test tools intended to debug reproducibility. Furthermore, it was announced that Bernhard s work on a 100% reproducible openSUSE-based distribution will be funded by NLnet.
He also posted another monthly report for his reproducibility work in openSUSE.
In GNU Guix, Janneke Nieuwenhuizen submitted a patch set for creating a reproducible source tarball for Guix. That is to say, ensuring that make dist is reproducible when run from Git. [ ]
Lastly, in Fedora, a new wiki page was created to propose a change to the distribution. Titled Changes/ReproduciblePackageBuilds , the page summarises itself as a proposal whereby A post-build cleanup is integrated into the RPM build process so that common causes of build irreproducibility in packages are removed, making most of Fedora packages reproducible.
Mailing list news
On our mailing list this month:
-
Continuing a thread started in March 2024 about the Arch Linux minimal container now being 100% reproducible, John Gilmore followed up with a post about the practical and philosophical distinctions of local vs. remote storage of the various artifacts needed to build packages.
-
Chris Lamb asked the list which conferences readers are attending these days: After peak Covid and other industry-wide changes, conferences are no longer the must attend events they previously were especially in the area of software supply-chain security. In rough, practical terms, it seems harder to justify conference travel today than it did in mid-2019. The thread generated a number of responses which would be of interest to anyone planning travel in Q3 and Q4 of 2024.
-
James Addison wrote to the list about a quirk in Git related to its
core.autocrlf functionality, thus helpfully passing on a slightly off-topic and perhaps not of direct relevance to anyone on the list today note that might still be the kind of issue that is useful to be aware of if-and-when puzzling over unexpected git content / checksum issues (situations that I do expect people on this list encounter from time-to-time) .
diffoscope
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 263, 264 and 265 to Debian and made the following additional changes:
- Don t crash on invalid
.zip files, even if we encounter their badness halfway through the file and not at the time of their initial opening. [ ]
- Prevent
odt2txt tests from always being skipped due to an (impossibly) new version requirement. [ ]
- Avoid parens-in-parens in test skipping messages. [ ]
- Ensure that tests with
>=-style version constraints actually print the tool name. [ ]
In addition, Fay Stegerman fixed a crash when there are (invalid) duplicate entries in .zip which was originally reported in Debian bug #1068705). [ ] Fay also added a user-visible note to a diff when there are duplicate entries in ZIP files [ ]. Lastly, Vagrant Cascadian added an external tool pointer for the zipdetails tool under GNU Guix [ ] and proposed updates to diffoscope in Guix as well [ ] which were merged as [264] [265], fixed a regression in test coverage and increased verbosity of the test suite[ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Chris Lamb:
- #1068173 filed against
pg-gvm.
- #1068176 filed against
goldendict-ng.
- #1068372 filed against
grokevt.
- #1068374 filed against
ttconv.
- #1068375 filed against
ludevit.
- #1068795 filed against
pympress.
- #1069168 filed against
sagemath-database-conway-polynomials.
- #1069169 filed against
gap-polymaking.
- #1069663 filed against
dub.
- #1069709 filed against
dpb.
- #1069784 filed against
python-itemloaders.
- #1069822 filed against
python-gvm.
-
Bernhard M. Wiedemann:
metis (fix build with nocheck)musique (fix a date-related issue)orthanc-volview (fix an issue with mtimes and sorting)go1.13, go1.14, go1.15 (fix a parallelism-related issue)postfish (disable compile-time benchmarking)geany/glfw (toolchain, random)edk2/ovmf/tianocore (with Joey Li: fix a date-related issue)dlib (report an issue with compile-time-CPU-detection)lua-lmod (fix a date-related issue)gitui (fix a date-related issue)openssl-3 (report an issue with random output)gcc14 (FTBFS-2038)nebula (FTBFS-2027-11-11)
-
Jan Zerebecki:
- rpm (Support reproducible automatic rebuilds, etc.)
- openSUSE-release-tools (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- pesign-obs-integration (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- openSUSE post-build-checks (Set
SOURCE_DATE_EPOCH)
- obs-build (Fix changelog timezone handling)
- obs-service-tar_scm (When generating changelog from Git, create the file if it does not exist.)
-
Thomas Goirand:
oslo.messaging (fix a hostname-related issue)
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, reprotest version 0.7.27 was uploaded to Debian unstable) by Vagrant Cascadian who made the following additional changes:
- Enable specific number of CPUs using
--vary=num_cpus.cpus=X. [ ]
- Consistently use 398 days for time variation, rather than choosing randomly each time. [ ]
- Disable builds of
arch:any packages. [ ]
- Update the description for the
build_path.path option in README.rst. [ ]
- Update escape sequences for compatibility with Python 3.12. (#1068853). [ ]
- Remove the generic upstream signing-key [ ] and update the packages signing key with the currently active team members [ ].
- Update the packaging
Standards-Version to 4.7.0. [ ]
In addition, Holger Levsen fixed some spelling errors detected by the spellintian tool [ ] and Vagrant Cascadian updated reprotest in GNU Guix to 0.7.27.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In April, an enormous number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Breakage detection:
- Exclude currently building packages from breakage detection. [ ]
- Be more noisy if diffoscope crashes. [ ]
- Health check: provide clickable URLs in jenkins job log for failed pkg builds due to diffoscope crashes. [ ]
- Limit graph to about the last 100 days of breakages only. [ ]
- Fix all found files with bad permissions. [ ]
- Prepare dealing with diffoscope timeouts. [ ]
- Detect more cases of failure to debootstrap base system. [ ]
- Include timestamps of failed job runs. [ ]
-
Documentation updates:
- Document how to access arm64 nodes at Codethink. [ ]
- Document how to use infomaniak.cloud. [ ]
- Drop notes about long stalled LeMaker HiKey960 boards sponsored by HPE and hosted at ETH. [ ]
- Mention
osuosl4 and osuosl5 and explain their usage. [ ]
- Mention that some packages are built differently. [ ][ ]
- Improve language in a comment. [ ]
- Add more notes how to query resource usage from
infomaniak.cloud. [ ]
-
Node maintenance:
-
Misc changes:
In addition, Mattia Rizzolo added some new host details. [ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
libntlm now releasing minimal source-only tarballs
Simon Josefsson wrote on his blog this month that, going forward, the libntlm project will now be releasing what they call minimal source-only tarballs :
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. [The] risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions [ship] generated files coming from the tarball into the binarySimon s post goes into further details how this was achieved, and describes some potential caveats and counters some expected responses as well. A shorter version can be found in the announcement for the 1.8 release of*.debor*.rpmpackage file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built[.]
libntlm.
Distribution work
In Debian this month, Helmut Grohne filed a bug suggesting the removal of dh-buildinfo, a tool to generate and distribute .buildinfo-like files within binary packages. Note that this is distinct from the .buildinfo generation performed by dpkg-genbuildinfo. By contrast, the entirely optional dh-buildinfo generated a debian/buildinfo file that would be shipped within binary packages as /usr/share/doc/package/buildinfo_$arch.gz.
Adrian Bunk recently asked about including source hashes in Debian s .buildinfo files, which prompted Guillem Jover to refresh some old patches to dpkg to make this possible, which revealed some quirks Vagrant Cascadian discovered when testing.
In addition, 21 reviews of Debian packages were added, 22 were updated and 16 were removed this month adding to our knowledge about identified issues. A number issue types have been added, such as new random_temporary_filenames_embedded_by_mesonpy and timestamps_added_by_librime toolchain issues.
In openSUSE, it was announced that their Factory distribution enabled bit-by-bit reproducible builds for almost all parts of the package. Previously, more parts needed to be ignored when comparing package files, but now only the signature needs to be deleted.
In addition, Bernhard M. Wiedemann published theunreproduciblepackage as a proper .rpm package which it allows to better test tools intended to debug reproducibility. Furthermore, it was announced that Bernhard s work on a 100% reproducible openSUSE-based distribution will be funded by NLnet.
He also posted another monthly report for his reproducibility work in openSUSE.
In GNU Guix, Janneke Nieuwenhuizen submitted a patch set for creating a reproducible source tarball for Guix. That is to say, ensuring that make dist is reproducible when run from Git. [ ]
Lastly, in Fedora, a new wiki page was created to propose a change to the distribution. Titled Changes/ReproduciblePackageBuilds , the page summarises itself as a proposal whereby A post-build cleanup is integrated into the RPM build process so that common causes of build irreproducibility in packages are removed, making most of Fedora packages reproducible.
Mailing list news
On our mailing list this month:
-
Continuing a thread started in March 2024 about the Arch Linux minimal container now being 100% reproducible, John Gilmore followed up with a post about the practical and philosophical distinctions of local vs. remote storage of the various artifacts needed to build packages.
-
Chris Lamb asked the list which conferences readers are attending these days: After peak Covid and other industry-wide changes, conferences are no longer the must attend events they previously were especially in the area of software supply-chain security. In rough, practical terms, it seems harder to justify conference travel today than it did in mid-2019. The thread generated a number of responses which would be of interest to anyone planning travel in Q3 and Q4 of 2024.
-
James Addison wrote to the list about a quirk in Git related to its
core.autocrlf functionality, thus helpfully passing on a slightly off-topic and perhaps not of direct relevance to anyone on the list today note that might still be the kind of issue that is useful to be aware of if-and-when puzzling over unexpected git content / checksum issues (situations that I do expect people on this list encounter from time-to-time) .
diffoscope
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 263, 264 and 265 to Debian and made the following additional changes:
- Don t crash on invalid
.zip files, even if we encounter their badness halfway through the file and not at the time of their initial opening. [ ]
- Prevent
odt2txt tests from always being skipped due to an (impossibly) new version requirement. [ ]
- Avoid parens-in-parens in test skipping messages. [ ]
- Ensure that tests with
>=-style version constraints actually print the tool name. [ ]
In addition, Fay Stegerman fixed a crash when there are (invalid) duplicate entries in .zip which was originally reported in Debian bug #1068705). [ ] Fay also added a user-visible note to a diff when there are duplicate entries in ZIP files [ ]. Lastly, Vagrant Cascadian added an external tool pointer for the zipdetails tool under GNU Guix [ ] and proposed updates to diffoscope in Guix as well [ ] which were merged as [264] [265], fixed a regression in test coverage and increased verbosity of the test suite[ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Chris Lamb:
- #1068173 filed against
pg-gvm.
- #1068176 filed against
goldendict-ng.
- #1068372 filed against
grokevt.
- #1068374 filed against
ttconv.
- #1068375 filed against
ludevit.
- #1068795 filed against
pympress.
- #1069168 filed against
sagemath-database-conway-polynomials.
- #1069169 filed against
gap-polymaking.
- #1069663 filed against
dub.
- #1069709 filed against
dpb.
- #1069784 filed against
python-itemloaders.
- #1069822 filed against
python-gvm.
-
Bernhard M. Wiedemann:
metis (fix build with nocheck)musique (fix a date-related issue)orthanc-volview (fix an issue with mtimes and sorting)go1.13, go1.14, go1.15 (fix a parallelism-related issue)postfish (disable compile-time benchmarking)geany/glfw (toolchain, random)edk2/ovmf/tianocore (with Joey Li: fix a date-related issue)dlib (report an issue with compile-time-CPU-detection)lua-lmod (fix a date-related issue)gitui (fix a date-related issue)openssl-3 (report an issue with random output)gcc14 (FTBFS-2038)nebula (FTBFS-2027-11-11)
-
Jan Zerebecki:
- rpm (Support reproducible automatic rebuilds, etc.)
- openSUSE-release-tools (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- pesign-obs-integration (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- openSUSE post-build-checks (Set
SOURCE_DATE_EPOCH)
- obs-build (Fix changelog timezone handling)
- obs-service-tar_scm (When generating changelog from Git, create the file if it does not exist.)
-
Thomas Goirand:
oslo.messaging (fix a hostname-related issue)
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, reprotest version 0.7.27 was uploaded to Debian unstable) by Vagrant Cascadian who made the following additional changes:
- Enable specific number of CPUs using
--vary=num_cpus.cpus=X. [ ]
- Consistently use 398 days for time variation, rather than choosing randomly each time. [ ]
- Disable builds of
arch:any packages. [ ]
- Update the description for the
build_path.path option in README.rst. [ ]
- Update escape sequences for compatibility with Python 3.12. (#1068853). [ ]
- Remove the generic upstream signing-key [ ] and update the packages signing key with the currently active team members [ ].
- Update the packaging
Standards-Version to 4.7.0. [ ]
In addition, Holger Levsen fixed some spelling errors detected by the spellintian tool [ ] and Vagrant Cascadian updated reprotest in GNU Guix to 0.7.27.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In April, an enormous number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Breakage detection:
- Exclude currently building packages from breakage detection. [ ]
- Be more noisy if diffoscope crashes. [ ]
- Health check: provide clickable URLs in jenkins job log for failed pkg builds due to diffoscope crashes. [ ]
- Limit graph to about the last 100 days of breakages only. [ ]
- Fix all found files with bad permissions. [ ]
- Prepare dealing with diffoscope timeouts. [ ]
- Detect more cases of failure to debootstrap base system. [ ]
- Include timestamps of failed job runs. [ ]
-
Documentation updates:
- Document how to access arm64 nodes at Codethink. [ ]
- Document how to use infomaniak.cloud. [ ]
- Drop notes about long stalled LeMaker HiKey960 boards sponsored by HPE and hosted at ETH. [ ]
- Mention
osuosl4 and osuosl5 and explain their usage. [ ]
- Mention that some packages are built differently. [ ][ ]
- Improve language in a comment. [ ]
- Add more notes how to query resource usage from
infomaniak.cloud. [ ]
-
Node maintenance:
-
Misc changes:
In addition, Mattia Rizzolo added some new host details. [ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
- Continuing a thread started in March 2024 about the Arch Linux minimal container now being 100% reproducible, John Gilmore followed up with a post about the practical and philosophical distinctions of local vs. remote storage of the various artifacts needed to build packages.
- Chris Lamb asked the list which conferences readers are attending these days: After peak Covid and other industry-wide changes, conferences are no longer the must attend events they previously were especially in the area of software supply-chain security. In rough, practical terms, it seems harder to justify conference travel today than it did in mid-2019. The thread generated a number of responses which would be of interest to anyone planning travel in Q3 and Q4 of 2024.
-
James Addison wrote to the list about a quirk in Git related to its
core.autocrlffunctionality, thus helpfully passing on a slightly off-topic and perhaps not of direct relevance to anyone on the list today note that might still be the kind of issue that is useful to be aware of if-and-when puzzling over unexpected git content / checksum issues (situations that I do expect people on this list encounter from time-to-time) .
diffoscope
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 263, 264 and 265 to Debian and made the following additional changes:
- Don t crash on invalid
.zip files, even if we encounter their badness halfway through the file and not at the time of their initial opening. [ ]
- Prevent
odt2txt tests from always being skipped due to an (impossibly) new version requirement. [ ]
- Avoid parens-in-parens in test skipping messages. [ ]
- Ensure that tests with
>=-style version constraints actually print the tool name. [ ]
In addition, Fay Stegerman fixed a crash when there are (invalid) duplicate entries in .zip which was originally reported in Debian bug #1068705). [ ] Fay also added a user-visible note to a diff when there are duplicate entries in ZIP files [ ]. Lastly, Vagrant Cascadian added an external tool pointer for the zipdetails tool under GNU Guix [ ] and proposed updates to diffoscope in Guix as well [ ] which were merged as [264] [265], fixed a regression in test coverage and increased verbosity of the test suite[ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Chris Lamb:
- #1068173 filed against
pg-gvm.
- #1068176 filed against
goldendict-ng.
- #1068372 filed against
grokevt.
- #1068374 filed against
ttconv.
- #1068375 filed against
ludevit.
- #1068795 filed against
pympress.
- #1069168 filed against
sagemath-database-conway-polynomials.
- #1069169 filed against
gap-polymaking.
- #1069663 filed against
dub.
- #1069709 filed against
dpb.
- #1069784 filed against
python-itemloaders.
- #1069822 filed against
python-gvm.
-
Bernhard M. Wiedemann:
metis (fix build with nocheck)musique (fix a date-related issue)orthanc-volview (fix an issue with mtimes and sorting)go1.13, go1.14, go1.15 (fix a parallelism-related issue)postfish (disable compile-time benchmarking)geany/glfw (toolchain, random)edk2/ovmf/tianocore (with Joey Li: fix a date-related issue)dlib (report an issue with compile-time-CPU-detection)lua-lmod (fix a date-related issue)gitui (fix a date-related issue)openssl-3 (report an issue with random output)gcc14 (FTBFS-2038)nebula (FTBFS-2027-11-11)
-
Jan Zerebecki:
- rpm (Support reproducible automatic rebuilds, etc.)
- openSUSE-release-tools (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- pesign-obs-integration (Create changelog for generated package sources for
SOURCE_DATE_EPOCH)
- openSUSE post-build-checks (Set
SOURCE_DATE_EPOCH)
- obs-build (Fix changelog timezone handling)
- obs-service-tar_scm (When generating changelog from Git, create the file if it does not exist.)
-
Thomas Goirand:
oslo.messaging (fix a hostname-related issue)
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, reprotest version 0.7.27 was uploaded to Debian unstable) by Vagrant Cascadian who made the following additional changes:
- Enable specific number of CPUs using
--vary=num_cpus.cpus=X. [ ]
- Consistently use 398 days for time variation, rather than choosing randomly each time. [ ]
- Disable builds of
arch:any packages. [ ]
- Update the description for the
build_path.path option in README.rst. [ ]
- Update escape sequences for compatibility with Python 3.12. (#1068853). [ ]
- Remove the generic upstream signing-key [ ] and update the packages signing key with the currently active team members [ ].
- Update the packaging
Standards-Version to 4.7.0. [ ]
In addition, Holger Levsen fixed some spelling errors detected by the spellintian tool [ ] and Vagrant Cascadian updated reprotest in GNU Guix to 0.7.27.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In April, an enormous number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Breakage detection:
- Exclude currently building packages from breakage detection. [ ]
- Be more noisy if diffoscope crashes. [ ]
- Health check: provide clickable URLs in jenkins job log for failed pkg builds due to diffoscope crashes. [ ]
- Limit graph to about the last 100 days of breakages only. [ ]
- Fix all found files with bad permissions. [ ]
- Prepare dealing with diffoscope timeouts. [ ]
- Detect more cases of failure to debootstrap base system. [ ]
- Include timestamps of failed job runs. [ ]
-
Documentation updates:
- Document how to access arm64 nodes at Codethink. [ ]
- Document how to use infomaniak.cloud. [ ]
- Drop notes about long stalled LeMaker HiKey960 boards sponsored by HPE and hosted at ETH. [ ]
- Mention
osuosl4 and osuosl5 and explain their usage. [ ]
- Mention that some packages are built differently. [ ][ ]
- Improve language in a comment. [ ]
- Add more notes how to query resource usage from
infomaniak.cloud. [ ]
-
Node maintenance:
-
Misc changes:
In addition, Mattia Rizzolo added some new host details. [ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
.zip files, even if we encounter their badness halfway through the file and not at the time of their initial opening. [ ]odt2txt tests from always being skipped due to an (impossibly) new version requirement. [ ]>=-style version constraints actually print the tool name. [ ]-
Chris Lamb:
- #1068173 filed against
pg-gvm. - #1068176 filed against
goldendict-ng. - #1068372 filed against
grokevt. - #1068374 filed against
ttconv. - #1068375 filed against
ludevit. - #1068795 filed against
pympress. - #1069168 filed against
sagemath-database-conway-polynomials. - #1069169 filed against
gap-polymaking. - #1069663 filed against
dub. - #1069709 filed against
dpb. - #1069784 filed against
python-itemloaders. - #1069822 filed against
python-gvm.
- #1068173 filed against
-
Bernhard M. Wiedemann:
metis(fix build with nocheck)musique(fix a date-related issue)orthanc-volview(fix an issue with mtimes and sorting)go1.13,go1.14,go1.15(fix a parallelism-related issue)postfish(disable compile-time benchmarking)geany/glfw(toolchain, random)edk2/ovmf/tianocore(with Joey Li: fix a date-related issue)dlib(report an issue with compile-time-CPU-detection)lua-lmod(fix a date-related issue)gitui(fix a date-related issue)openssl-3(report an issue with random output)gcc14(FTBFS-2038)nebula(FTBFS-2027-11-11)
-
Jan Zerebecki:
- rpm (Support reproducible automatic rebuilds, etc.)
- openSUSE-release-tools (Create changelog for generated package sources for
SOURCE_DATE_EPOCH) - pesign-obs-integration (Create changelog for generated package sources for
SOURCE_DATE_EPOCH) - openSUSE post-build-checks (Set
SOURCE_DATE_EPOCH) - obs-build (Fix changelog timezone handling)
- obs-service-tar_scm (When generating changelog from Git, create the file if it does not exist.)
-
Thomas Goirand:
oslo.messaging(fix a hostname-related issue)
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, reprotest version 0.7.27 was uploaded to Debian unstable) by Vagrant Cascadian who made the following additional changes:
- Enable specific number of CPUs using
--vary=num_cpus.cpus=X. [ ]
- Consistently use 398 days for time variation, rather than choosing randomly each time. [ ]
- Disable builds of
arch:any packages. [ ]
- Update the description for the
build_path.path option in README.rst. [ ]
- Update escape sequences for compatibility with Python 3.12. (#1068853). [ ]
- Remove the generic upstream signing-key [ ] and update the packages signing key with the currently active team members [ ].
- Update the packaging
Standards-Version to 4.7.0. [ ]
In addition, Holger Levsen fixed some spelling errors detected by the spellintian tool [ ] and Vagrant Cascadian updated reprotest in GNU Guix to 0.7.27.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In April, an enormous number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Breakage detection:
- Exclude currently building packages from breakage detection. [ ]
- Be more noisy if diffoscope crashes. [ ]
- Health check: provide clickable URLs in jenkins job log for failed pkg builds due to diffoscope crashes. [ ]
- Limit graph to about the last 100 days of breakages only. [ ]
- Fix all found files with bad permissions. [ ]
- Prepare dealing with diffoscope timeouts. [ ]
- Detect more cases of failure to debootstrap base system. [ ]
- Include timestamps of failed job runs. [ ]
-
Documentation updates:
- Document how to access arm64 nodes at Codethink. [ ]
- Document how to use infomaniak.cloud. [ ]
- Drop notes about long stalled LeMaker HiKey960 boards sponsored by HPE and hosted at ETH. [ ]
- Mention
osuosl4 and osuosl5 and explain their usage. [ ]
- Mention that some packages are built differently. [ ][ ]
- Improve language in a comment. [ ]
- Add more notes how to query resource usage from
infomaniak.cloud. [ ]
-
Node maintenance:
-
Misc changes:
In addition, Mattia Rizzolo added some new host details. [ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
--vary=num_cpus.cpus=X. [ ]arch:any packages. [ ]build_path.path option in README.rst. [ ]Standards-Version to 4.7.0. [ ]
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In April, an enormous number of changes were made by Holger Levsen:
- Debian-related changes:
-
Breakage detection:
- Exclude currently building packages from breakage detection. [ ]
- Be more noisy if diffoscope crashes. [ ]
- Health check: provide clickable URLs in jenkins job log for failed pkg builds due to diffoscope crashes. [ ]
- Limit graph to about the last 100 days of breakages only. [ ]
- Fix all found files with bad permissions. [ ]
- Prepare dealing with diffoscope timeouts. [ ]
- Detect more cases of failure to debootstrap base system. [ ]
- Include timestamps of failed job runs. [ ]
-
Documentation updates:
- Document how to access arm64 nodes at Codethink. [ ]
- Document how to use infomaniak.cloud. [ ]
- Drop notes about long stalled LeMaker HiKey960 boards sponsored by HPE and hosted at ETH. [ ]
- Mention
osuosl4andosuosl5and explain their usage. [ ] - Mention that some packages are built differently. [ ][ ]
- Improve language in a comment. [ ]
- Add more notes how to query resource usage from
infomaniak.cloud. [ ]
- Node maintenance:
- Misc changes:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-buildsonirc.oftc.net. - Twitter: @ReproBuilds
- Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org


























 Reduce the size of your c: partition to the smallest it can be and then turn off windows with the understanding that you will never boot this system on the iron ever again.
Reduce the size of your c: partition to the smallest it can be and then turn off windows with the understanding that you will never boot this system on the iron ever again. To find the literal path names of your detected drives you can run fdisk -l. Pay attention to the names of the partitions and the sizes of the drives to help determine which is which.
Once you have a shell in the netinst installer, you should maybe be able to run a command like the following. This will duplicate the disk located at if (in file) to the disk located at of (out file) while showing progress as the status.
To find the literal path names of your detected drives you can run fdisk -l. Pay attention to the names of the partitions and the sizes of the drives to help determine which is which.
Once you have a shell in the netinst installer, you should maybe be able to run a command like the following. This will duplicate the disk located at if (in file) to the disk located at of (out file) while showing progress as the status.
 In the New VM window, select Import existing disk image
In the New VM window, select Import existing disk image 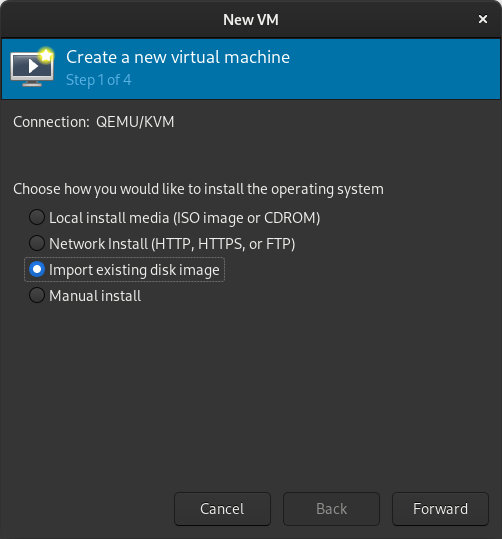 When prompted for the path to the image, use the one we created with sudo qemu-img convert above.
When prompted for the path to the image, use the one we created with sudo qemu-img convert above.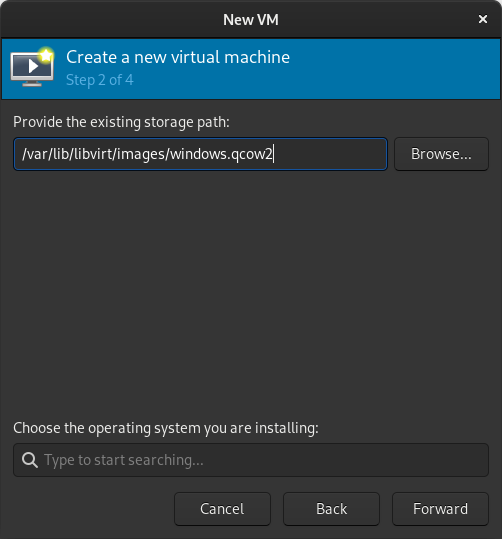 Select the version of Windows you want.
Select the version of Windows you want.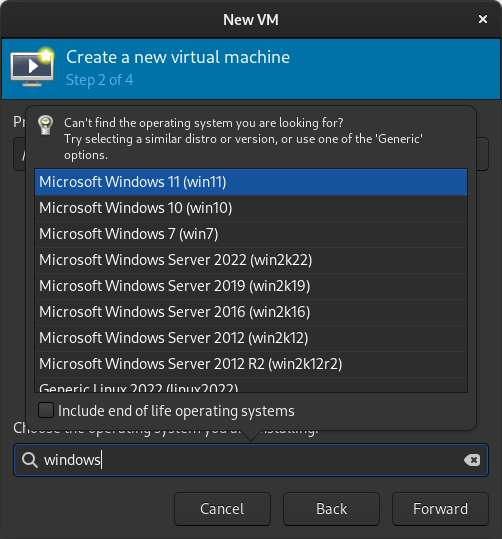 Select memory and CPUs to allocate to the VM.
Select memory and CPUs to allocate to the VM.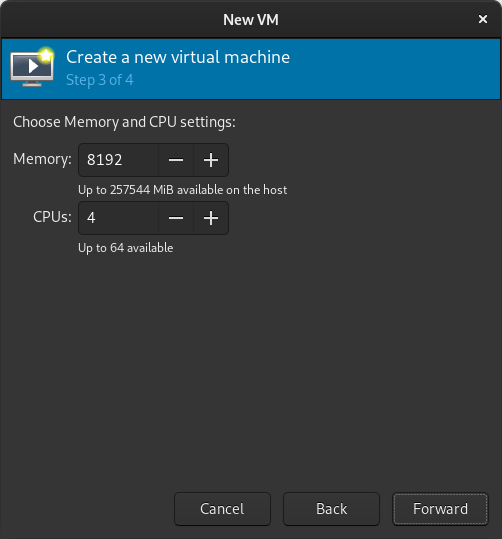 Tick the Customize configuration before install box
Tick the Customize configuration before install box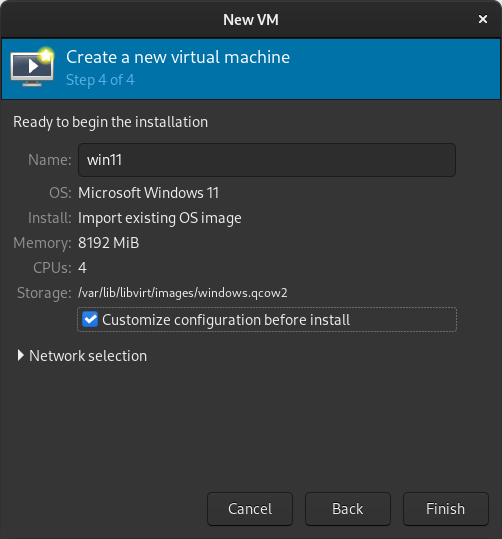 If you re prompted to enable the default network, do so now.
If you re prompted to enable the default network, do so now.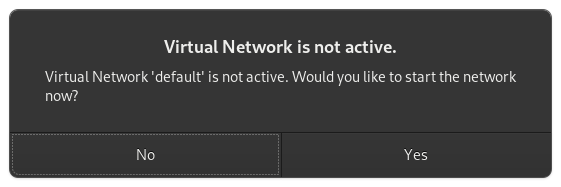 The default hardware layout should probably suffice. Get it as close to the underlying hardware as it is convenient to do. But Windows is pretty lenient these days about virtualizing licensed windows instances so long as they re not running in more than one place at a time.
The default hardware layout should probably suffice. Get it as close to the underlying hardware as it is convenient to do. But Windows is pretty lenient these days about virtualizing licensed windows instances so long as they re not running in more than one place at a time.
 Good luck! Leave comments if you have questions.
Good luck! Leave comments if you have questions.














 Holger Levsen: Welcome, David, thanks for taking the time to talk with us today. First, could you briefly tell me about yourself?
David: Sure! I m David A. Wheeler and
I work for the
Holger Levsen: Welcome, David, thanks for taking the time to talk with us today. First, could you briefly tell me about yourself?
David: Sure! I m David A. Wheeler and
I work for the 








 Hans: One key difference to the Google Play Store is that F-Droid does not ship proprietary software by default. All apps shipped from
Hans: One key difference to the Google Play Store is that F-Droid does not ship proprietary software by default. All apps shipped from